One thing I keep running into is the claim that "PHP is out of fashion," which I don't quite understand considering PHP is the most popular server-side language on the entire Internet, and many of the top websites in the world use it. Indeed, even on Twitter recently I had this conversation (edited for readability, see link for context):
Faizan Javed (@faizanj): A bigger issue – what is it with valley startups and PHP? Tony Showoff (@TonyShowoff): What do you mean? The polarisation of it, to where either it's evil or it's the only thing used? Faizan Javed (@faizanj): the intense focus and controversy over an arguably out-of-fashion language. Tony Showoff (@TonyShowoff): Java is also "out of fashion" but still used, PHP is used by more web sites than any other language. I think it's inadequacy. A lot of things go in and out of fashion, but fashion doesn't reflect usefulness. Remember the coming p2p/push/xml/etc revolutions? Faizan Javed (@faizanj): one can argue Cobol and Fortran are also still useful in their domains. But hip, cool and mainstream they are not. Tony Showoff (@TonyShowoff): So is hand looming one could say, but half of all internet sites don't use COBOL and half of looms aren't hand driven.
Like underwear, PHP is becoming cleaner, as if it's been washed with Tempa-Cheer on double rinse at high heat.
I think he does bring up a good point and question though. Are COBOL and Fortran fashionable at all since they still are in use, mostly in the realm of maintenance? Well, maybe, but I don't think so. As I tried to point out as best I could on Twitter, niche use cases are not the same thing as something being ubiquitous. Just as you can still find handloomers that doesn't mean machine looming is falling out of fashion, despite the rise in custom hand made items on etsy.com
I think people often confuse what's cool with what's in fashion and what's useful or available. This is less of a big deal in pop culture trends, but in the computer world it doesn't really make much sense. Sure, PHP may not be cool, I'm not sure if it ever was, but that doesn't change the fact that to this day when you want to find a web host, almost always they have PHP hosting available and not much, if anything else. Despite Python and Ruby becoming more hip, along with Erlang and the less useful other things which are some goofy spin off of another thing, they simply aren't available everywhere or ubiquitous.
So, in a sense, asking whether or not PHP is in fashion is sort of like asking whether or not underwear is in fashion. Sure it may be cool, or sexy, not to wear it, but for the most part you'll find it everywhere you look. Is that a bad analogy for PHP? Maybe, but reflecting PHP's problems over the years, I think it's pretty apt, but like underwear, PHP is becoming cleaner, as if it's been washed with Tempa-Cheer on double rinse at high heat.
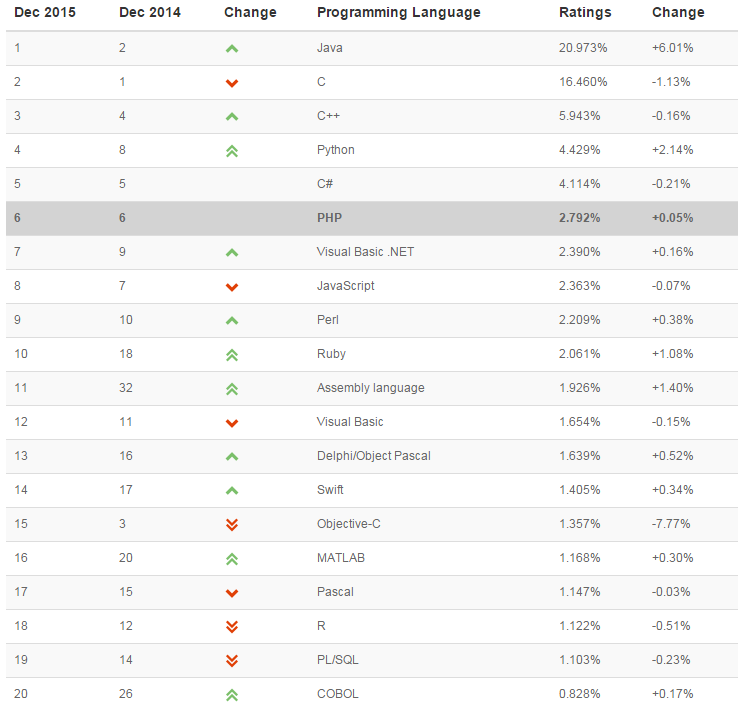
But what about the numbers (click image for source information)?
And finally, what about as far as community help goes? After all, a programming language's success and usability these days often relies on thriving communities. Well…
Uncool? Maybe, but no programming language has ever been cool. Out of fashion? I don't think so.
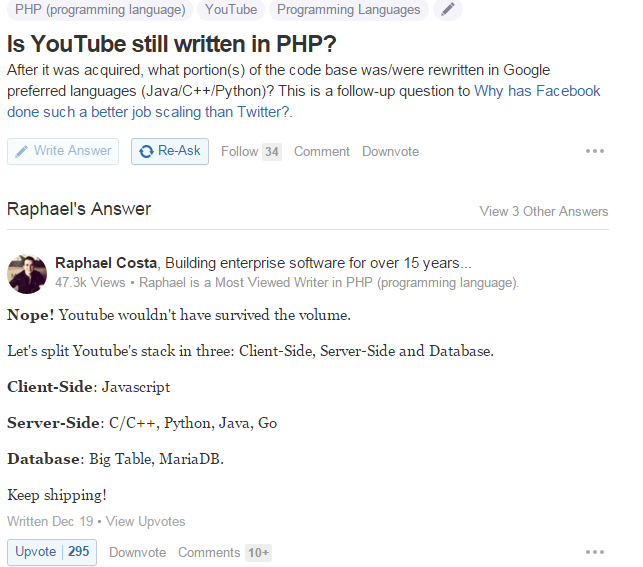
I get Quora summary emails despite not being a Quora user, and sometimes I see very interesting questions, and more often than not very incompetent answers… rather, incompetent answers written very well so they sound like they could be correct. Here's one example:
Well, as most of you know, YouTube was never written in PHP, and they could've gained this much by just looking up YouTube on Wikipedia. I think the second part of the question is an interesting one, however the answer is dog shit.
Primarily because it's a question of scalability with two different types of platforms. Sure, Twitter and Facebook seem similar enough. They're both web sites full of assholes bragging about themselves (myself included) and old guys and oily nice guys trying to pick up strange, but their problems are completely different.
So, this is a classic thing of "anything is faster/better than PHP so therefore if it used PHP it would've failed," which is totally stupid and based on nonsense.
Twitter works in ever changing content where historical entries are rarely retrieved, Facebook does pretty much the opposite. I suggest looking up the histories of both how Twitter and Facebook have dealt with scalability on websites like highscalability.com and also YouTube has tons of videos where their engineers have discussed it. Note that you could only listen to information provided by actual Twitter and Facebook insiders, not random morons who think they've got it all figured out, that's why I'm not listing it all here myself.
YouTube could've survived the volume, because it survived with Python, which is slower than PHP in a lot of ways, but I think any actual developers reading this, whether or not they love or hate Python or PHP, know that YouTube's bottlenecks are database and bandwidth, not their code backend. And there's plenty of videos on YouTube of developers from there stating this very fact too.
So, this is a classic thing of "anything is faster/better than PHP so therefore if it used PHP it would've failed," which is totally stupid and based on nonsense. Sure, PHP used to really suck, especially in the days YouTube launched, but that has nothing to do with their success or failure.
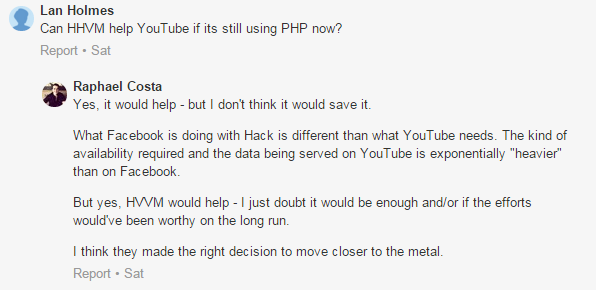
But oh it gets worse:
Facebook's HHVM still couldn't be enough? Well, Raphael Costa claims to have 15 years in enterprise software, and I believe it, because it would explain why most enterprise software systems are garbage, because their engineers are incompetent.
Let's just point out why this is nonsensical garbage:
Facebook used PHP and expanded with it beyond the popularity of YouTube, and yet YouTube couldn't have used it?
Facebook is more popular than YouTube, so this makes no damn sense at all. I guess I said that already.
Facebook also serves video.
Most importantly: serving video literally has not a fucking thing to do with the language you run on the backend, because you're serving them as flat files or from CDNs. This is true in the case of both YouTube and Facebook, and also your major online porn video sites.
Yet, his post gets the most upvotes, and he is considered authoritative. This is just one example of Quora really being no better than Yahoo answers, especially nowadays. I've never used Quora or contributed, and this is pretty much why.
I started working with PHP 7.0.0-dev and, at least at the time I wrote this, xdebug and Zend debugger are not currently compatible with it, because of the extension API changes. If you need something better than a simple NOTICE or ERROR, then this will probably work for you.
The code is fairly clean, but could use some improvements, and if you have any suggestions or insights, please comment.
Some Notes
Some really nice debugging classes and so forth exist (like kint), but they're huge and do way more than I need them to, and also most won't easily mimic xdebug, if at all.
It does not work as well or provide as much detail as xdebug's stack tracing, but it's pretty close and may work for most people.
It doesn't provide remote debugging or anything like that, obviously
The code, ironically, does not take advantage of any improves made within PHP 7, so it can be used with older versions, but I've only tested it with 5.5 and 5.6
Instructions
I put the code at the top of my entry point (index.php for me) before any other code (autoloader, etc). Of course if you don't have an entry point, you can probably put it in some other global file if you want, such as a config file.
I also put it in the condition of "if (PHP_MAJOR_VERSION == 7) {…}", just in case I test my app with other versions as well.
One of the biggest criticisms of PHP (aside from syntax) is the lack of any sort of scalar typing, weak, strong, doesn't really matter, it simply doesn't exist. A push in the right direction was the call for "scalar type hinting," which was laid out in this PHP RFC:
This topic, believe it or not, is a sensitive one, with some people being so against it that… well, I can't really think of an analogy, I don't know why the hell you'd be against it. Though some were against it just because they didn't like how this specific RFC defined how the PHP interpreter would know whether or not to do the actual type hinting.
Yes, they wanted to sink the idea because of a slightly related syntactical issue, instead of dealing with it later and implementing a very important thing.
The issue apparently caused so much grief that the major promoter, @AndreaFaulds has left PHP*:
This really sucks, and I find it to be truly disappointing. I think if we want to have PHP be taken more seriously by the broader programming world, we need to implement things that more "serious" languages have. I'm even more disappointed because I honestly thought that if this RFC did not pass, it may be years before anything close to type hinting on scalars is implemented in PHP, because it would create an untouchable issue like other things.
So, in the unlikelihood that other PHP developers are reading this, please keep pushing for scalar type hinting or something at least approaching that, and if you're a developer in PHP, keep asking for it, I know I will.
If no RFC is submitted for scalar typing in PHP 7, I'm probably going to switch languages, maybe Go or something, I don't know. I've been using PHP since 2002, and I've been waiting too damn long.
*Furthermore I think Andrea Faulds leaving PHP is sad because she promoted really good ideas and defined them very well in her RFCs. I think this is a language set back, but there are still a lot of great people on the PHP team, but I have to be honest and say I was really wanting to see all of her recent RFCs pass, they were all things I was also heavily interested in.
When it comes to character support I think the only thing that should ever be used is Unicode. That's right, I said it. However, when it comes to support in MySQL, things get a little bit murky.
I never had too much of an issue using plain ol' utf8_general_ci, however when trying to add language support for Gothic (tested because it's rare), I ran into a serious issue:
This issue is caused by the fact UTF-8 in MySQL isn't fully supported by utf8 the character set, it only supports a maximum of 3-byte characters. If you want something more realistic you're going to need to have at least MySQL 5.5.3 and you're going to have to use utf8mb4 not regular utf8. Yes, seriously.
Make sure you read through all this before trying anything, because there are edge issues, especially with indices (indexes) which you may need to consider.
Also back up your data first.
Updating Database
I'll be working under the assumption that you want your entire database to be utf8mb4, but if you don't then you'll have to adjust a bit, but seriously reconsider joining the 21st century if you're not using unicode. I'm also assuming you want case insensitive text, and if you don't, replace utf8mb4_unicode_ci with utf8mb4_bin — most people want case insensitive text in most cases.
Update the default character set and collation for your database:
ALTER DATABASE `mydatabase` CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Updating Tables
First we need to change the default character set, this way when you add new columns in the future, or whatever, you don't need to worry about adding all of the character set specification:
ALTER TABLE `mytable1` DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Updating Table Columns
Now, you can convert one column at a time, and this may be what you wish to do if you require different character sets for your CHAR, VARCHAR, and TEXT columns, here's how you do that:
ALTER TABLE `mytable1` CHANGE `mycolumn` `mycolumn` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL DEFAULT '';
Now obviously you're going to want to make sure that you're converting to the same column type and length, etc, the above is for example only and if you copy/paste it, you may screw up your column schema. Essentially you're just using ALTER TABLE CHANGE on the column in order to change the character set to utf8mb4 and collation to utf8mb4_unicode_ci.
If on the other hand you just want to change the entire the entire table at once, you can do:
ALTER TABLE `mytable1` CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
Updating Table Indices
When changing the character type, you may run into this on InnoDB:
ERROR 1071 (42000): Specified key was too long; max key length is 767 bytes
or this on MyISAM:
ERROR 1071 (42000): Specified key was too long; max key length is 1000 bytes
Ah, CRAP!
Oh snippy snap, snap, there are solutions:
If you're using InnoDB on MySQL 5.6.3 or higher you can enable innodb_large_prefix in your MySQL config file (more information in manual here), but if you aren't you can take a few steps to work it out the old way:
Make note of the conflicting index, it's going to likely be one which is something like VARCHAR(255) or an index across multiple columns which includes VARCHAR. Make note of the index name, type, and which column(s) it crosses.
In my own scenario, I had a lot of columns which included some sort of VARCHAR(254) and ID which was binary(20). Now it seems like 254+20 = 274, and hey that's less than 767 (or 1000) so what's the deal?Well, not so fast there, Professor.MySQL doesn't count literal bytes in VARCHAR when it comes to Unicode, rather potential Unicode bytes are themselves counted as a byte (wait, what?).So if the column is 254 and it's utf8 that means the actual potential length is literally (254 * 3) bytes, and with utf8mb4 it's (254 * 4). So really the length of the key you're trying to create is ((254 * 4) + 20).InnoDB only allows a maximum of 255 bytes for the column in an index with utf8 and 191 bytes for utf8mb4.So if you need the entire column indexed, you aren't going to want to change the character set for that column(s), and instead I recommend changing all others one by one (as seen in the Table Columns section) rather than trying to convert the entire table. However if you do not need the entire column to be index, and in certain cases I did not.Drop the index:
ALTER TABLE `mytable1` DROP INDEX `theindex`;
Then recreate it with the offending column(s) limited to 191:
ALTER TABLE `mytable1` ADD INDEX `theindex` (`mycolumn` (191));
or if across multiple columns (assuming mycolumnb is not utf8 for example):
ALTER TABLE `mytable1` ADD INDEX `theindex` (`mycolumn` (191),`mycolumnb`);
As long as the indices are the same, and in the same column order, you should receive the same benefits for the indices without worrying about redoing your queries.
Additional Notes and Considerations
If a column is not being used for search and case insensitivity isn't an issue, instead of using CHAR or VARCHAR, I suggest using BINARY and VARBINARY. Not only is comparison vastly faster, but also there's less to worry about as far as character set issues go, i.e. they don't matter. Further also VARBINARY is literal length so the UTF-8 limitations described in the index section of this post do not apply, so you can get the full width for your index.
Additionally instead of using TEXT, use BLOB, for the same reasons, but also realise the same limitations apply, such as no fulltext searching.
In summation, if you don't need case sensitivity and you don't need fulltext search, consider BINARY, VARBINARY, and BLOB over CHAR, VARCHAR, and TEXT, it'll be a lot easier to deal with when it comes to Unicode.
Depending on your programming language, you may need to specify when connecting which chartype to use (you can also, in most cases, specify this on configuration, see that section at the bottom), this usually can be done by sending this query right after connection:
SET NAMES utf8mb4;
Configuration
You can edit your my.cnf (or my.ini on Windows) and make these changes to the appropriate sections of the configuration file (applicable to MySQL 5.6, older versions may need adjusted configuration):